Hash table ? Hashing?
해싱이란? (Hashing)
해싱이란 임의의 길이의 값을 해시함수(Hash Function)를 사용하여 고정된 크기의 값으로 변환하는 작업을 말한다.
해시 테이블이란? (Hash table)
해시 테이블이란 해시함수를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터(value)를 저장하는 자료구조를 말한다. 기본연산으로는 탐색(Search), 삽입(Insert), 삭제(Delete)가 있다.
간단한 테이블을 만들어서 보자면 key의 값을 주소로 사용하여 만드는 테이블을 말한다. 만일 key가 30이라면 배열의 인덱 30에 데이터를 저장시켜 놓는 방법이다 .
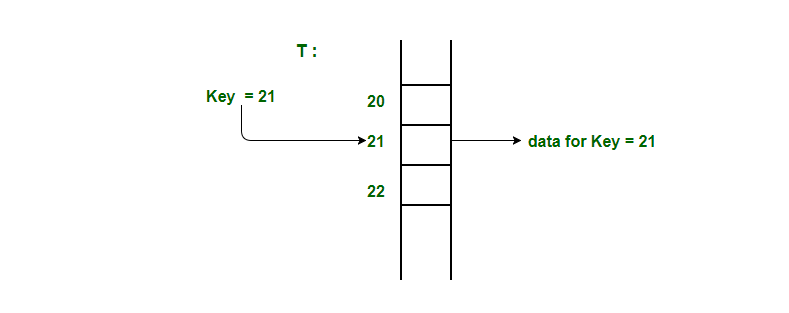
이렇게 테이블을 해시테이블을 만들어서 사용한다면 탐색,삽입,삭제 등 O(1) 시간 복잡도로 연산할 수 있다.
하지만 여기에서 해시테이블을 사용하기 위해선 몇가지 주의점이 있다.
1. 키 값의 최대가 얼마인지 알고 있어야한다.
2. 최대 키 값이 적을 때 좋은 성능을 보여준다 (최대 키 값이 커진다면 메모리 비용 상승)
3. 키 값이 골고루 분포되지 않는다면 메모리 낭비가 심해진다.
4. Key는 고유해야 하며, 만일 중복된 key 가 있으면 먼저 있던 key와 value를 대체한다.
5. 저장 순서를 보장하지 않으므로 순서에 의존적인 작업에는 적합하지 않을 수 있습니다.
해시테이블을 만드는 과정
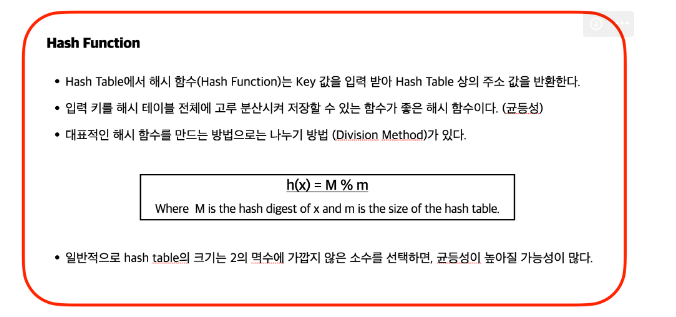
Hash Table에서 해시 함수는 입력된 Key를 table의 크기에 적합한 인덱스 값으로 변환하는 것이 목적이다.
만일 해시함수를 통해 해시한 값이 테이블의 크기를 벗어나게 된다면 사용 할 수 없음 (그래서 키 값의 최대가 얼마인지 알아야함 -> 변환 했을 때 범위 내에 존재하는지 알기 위해)



- Hash Table의 장점과 단점
- 장점
- 빠른 데이터 접근 속도 : 평균적으로 O(1)의 시간 복잡도로 조회 / 삽입 / 삭제를 수행
- 키-값 쌍 저장 : 키를 기반으로 데이터를 저장하고 검색하는 구조로, 데이터의 연관 관계를 보다 명확하고 쉽게 관리할 수 있음
- 중복 방지 : 키의 유일성을 통해 데이터의 중복을 자연스럽게 방지
- 단점
- 두 개 이상의 키가 동일한 해시 값을 가질 경우 충돌이 발생합니다. 충돌을 관리하는 많은 방법들이 있지만, 충돌이 빈번하게 발생할 경우 성능 저하를 가져올 수 있습니다.
- 장점
Hash Collision이란?
해시 테이블 내에 어떤 키가 이미 자리 잡고 있는 상태에서 다른 키가 삽입을 시도하는 경우에, 해시 함수가 서로 다른 입력에 대해 동일한 값을 반환하는 경우 Hash Collision 발생
- 해시 함수를 임의의 크기 값을 고정 해시값으로 변경하면서 중복될 수 있음
- 해시 함수를 나온 값이 table 크기의 범위를 넘어서는 경우가 발생 할 수 있음
해결 방법 1) Separate Chaning
- 같은 주소로 해싱되어 충돌이 일어나는 Entry를 연결 리스트(Linked List)로 연결해서 저장하는 방식으로 해시 충돌을 피할 수 있습니다.

- Chaning 방법에서 임의의 키에 해당하는 엔트리를 저장할 때는 해시값이 가리키는 bucket의 연결 리스트에 삽입
- 이때 내가 사용하고 있는 연결 리스트의 구현체에 따라서 맨 앞 혹은 끝에 삽입
해결 방법 2) Open Addressing
- Separate Chaning 방식과 달리 추가 공간을 사용하지 않고 충돌을 해결하는 방법입니다.

해시 출돌이 일어나도 정해진 hash table 공간에 다른 위치에 저장방법이다. 다른 위치에 저장함으로서 key로 해시 테이블을 때 buket에 들어있는 인덱스와 주소가 일치하지 않을 수 있다.
선형 탐색 (Linear Probing) - 가장 간단한 방법으로 메모리주소 다음 위치에 bucket을 저장하는 방법
Separate Chaning 해시테이블 (python)
(list로 해시인덱스 데이터 저장)
class Chaining_Hash_table:
def __init__(self,length= 97): # 97 테이블 크기만큼 나눈다
self.max_len = length #테이블 key를 97로 나누어 해싱
self.table = [[] for __ in range(length)]
def hash(self,key): #해시테이블에 key와 value넣기.
hash_key = sum([ord(i) for i in key])
return hash_key % self.max_len # #ord함수로 문자열 변경후 나온 값 % max_len
def add(self,key,value):
index = self.hash(key)
self.table[index].append((key,value))
def put(self,key,value):
index = self.hash(key)
if not value: #리스트 안의 값이 존재하지않는다면 None반환
return None
for i in range(len(value)): # 리스트에서 동일한 값 찾기
if value[i] == key:
value.pop(i) # pop으로 해시테이블 인덱스에 안에있는 튜플 제거
break
self.table[index].append((key,value)) # 수정할 데이터 추가,
def get(self,key):
index = self.hash(key)
value = self.table[index]
if not value: #리스트 안의 값이 존재하지않는다면 None반환
return None
for v in value: # 리스트에서 값을 찾아 반환
if v[0] == key:
return v[1]
Linear Probing 해시테이블 (python)
# ”Hash Table의 크기는 2의 멱수 (2^0, 2^1, 2^2...2^11에 가깝지 않은 소수(prime number)”를 선택하는 것이 좋습니다.
class Linear_Probing_Hash_table:
def __init__(self,length= 97): # 97 테이블 크기만큼 나눈다
self.max_len = length #테이블 key를 97로 나누어 해싱
self.table = [[0] for __ in range(length)]
def hash(self,key): #해시테이블에 key와 value넣기.
hash_key = sum([ord(i) for i in key])
return hash_key % self.max_len # #ord함수로 문자열 변경후 나온 값 % max_len
def add(self,key,value):
index = self.hash(key)
if self.table[index]!=0:
for i in range(index,self.max_len):
if self.table[i]==0:
self.table[i] = [key,value]
else:
self.table[index]=[key,value]
def put(self,key,value):
index = self.hash(key)
if self.table[index]==0:
return None # 데이터 존재하지 않음
else:
for i in range(index,self.max_len):
if self.table[i][0]==index: #변환된 인덱스부터 밑으로 내려가며 탐색
self.table[i] = [key,value] # 키가 동일하다면 값 변경 후 저장
return
def get(self,key):
index = self.hash(key)
if self.table[index]==0:
return None # 첫인덱스 조회시 데이터가 0이라면 데이터 존재하지 않음
else:
for i in range(index,self.max_len):
if self.table[i][0]==index: #변환된 인덱스부터 밑으로 내려가며 탐색
return self.table[i][1] # 키가 동일한 인덱스를 찾았다면 값 반환,
return None # 동일한 인덱스 범위에 다른 값이 있지만 동일한 값을 찾지 못했다면 None 반환
'CS > 자료구조' 카테고리의 다른 글
| Set의 시간복잡도 (0) | 2023.09.01 |
|---|---|
| python으로 LinkedList 만들기 (0) | 2023.08.30 |